3.2. Semantische interoperabilitieit1
3.2.1. Het probleem van semantische interoperabiliteit
Semantische interoperabiliteit gaat verder dan gedeelde gegevensformaten of gemeenschappelijke terminologieën - het vereist dat verschillende systemen uitgewisselde gegevens op dezelfde manier interpreteren. Het bereiken hiervan hangt af van hoe goed de ontologie van elk systeem de beoogde betekenis van de concepten die het gebruikt vastlegt. De volgende diagrammen illustreren hoe systemen kunnen verschillen in hun benadering van een gedeelde conceptualisatie, en hoe deze verschillen hun vermogen om betekenisvol samen te werken beïnvloeden.
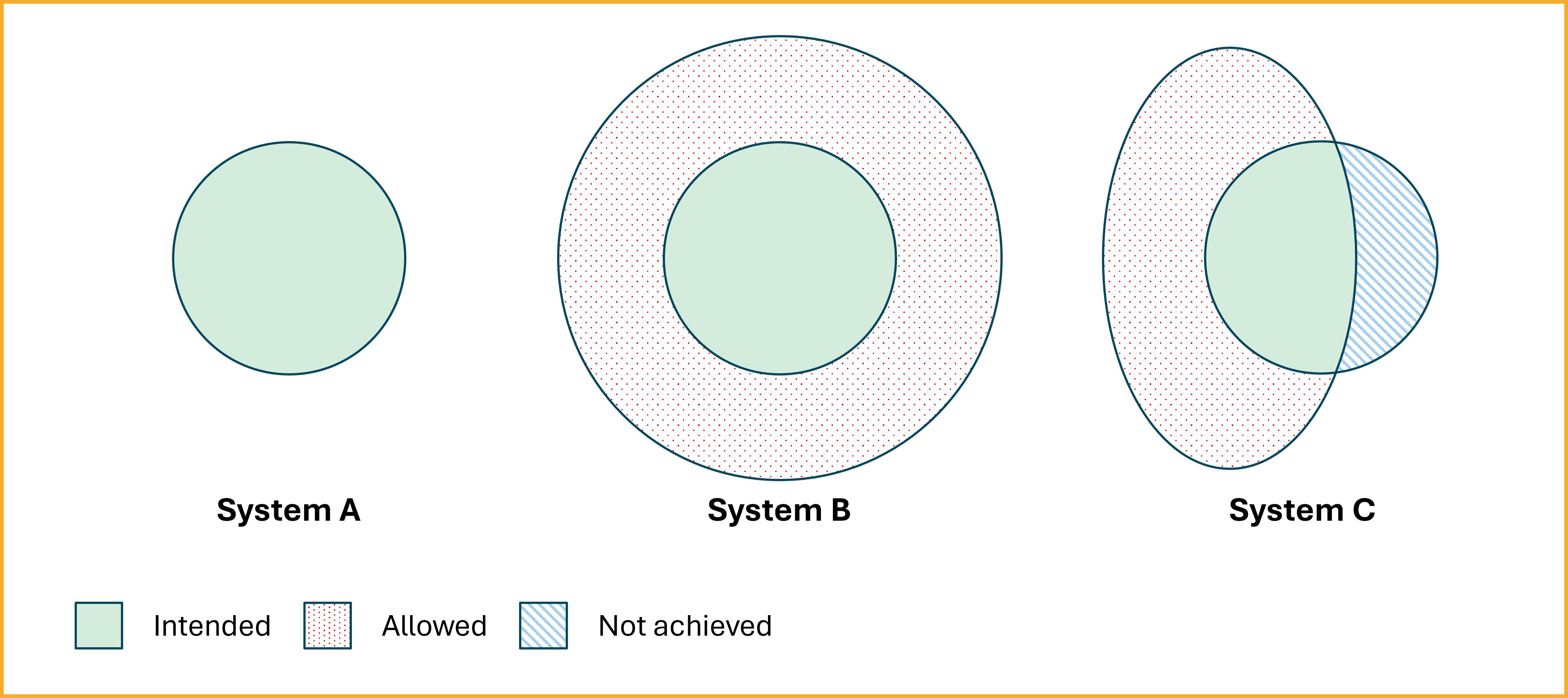
Bovenstaand diagram illustreert hoe drie verschillende systemen proberen dezelfde conceptualisatie te representeren - d.w.z. een gedeeld begrip van de echte wereld - maar met verschillende niveaus van succes. Elk systeem gebruikt een andere ontologie om zijn interne model te beperken, wat leidt tot verschillen in hoe getrouw ze de beoogde betekenis vastleggen.
-
Systeem A (links) vertegenwoordigt een ideaal geval. Zijn ontologie sluit nauw aan bij de beoogde semantiek (groene gebied), zonder extra interpretaties toe te voegen of geldige uit te sluiten. Dit wordt beschreven als een nauwe benadering van de beoogde modellen - een zeer wenselijke, hoewel vaak moeilijk te bereiken, situatie voor semantische interoperabiliteit.
-
Systeem B (midden) gebruikt een meer permissieve ontologie. Het rode gestippelde gebied toont onbedoelde modellen die logisch consistent zijn met het formalisme van Systeem B maar afwijken van de beoogde betekenis. Een dergelijke overgeneralisatie kan leiden tot valse overeenstemming: systemen die interoperabel lijken omdat ze hetzelfde vocabulaire gebruiken, maar de termen eigenlijk verschillend interpreteren.
-
Systeem C (rechts) maakt de tegenovergestelde fout. Zijn ontologie is te restrictief: het blauw gestreepte gebied vertegenwoordigt geldige betekenissen waarmee het geen rekening houdt. Dit kan gebeuren wanneer de beperkingen van een systeem te smal of onvolledig zijn, wat leidt tot de uitsluiting van noodzakelijke interpretaties en verlies van informatie.
Echte semantische interoperabiliteit vereist dus meer dan syntactische of logische afstemming. Het vereist een gedeeld wereldbeeld - een convergentie over wat bestaat, hoe het kan worden beschreven, en welke interpretaties geldig zijn.
3.2.2. Hoe wordt Semantische Interoperabiliteit Bereikt?
Het bereiken van semantische interoperabiliteit omvat verschillende stappen:
- Gestandaardiseerde vocabulaires en ontologieën: Gebruik van gedeelde terminologieën zoals SNOMED CT, LOINC, of domein-specifieke ontologieën om consistent begrip van gegevenselementen te waarborgen.
- Metadata en annotaties: Semantische lagen aan gegevens toevoegen met behulp van RDF, OWL of JSON-LD om context en betekenis te bieden.
- Mappings en afstemmingen: Links creëren tussen verschillende vocabulaires of datasets om gegevensintegratie en interoperabiliteit te vergemakkelijken.
- Tools en platformen: Gebruik van interoperabiliteitskaders, API's en kennisgrafen om naadloze gegevensuitwisseling en begrip te ondersteunen.
- Ontologisch gefundeerde talen: Gebruik van modelleertalen die helpen om de ontologische aannames die zijn ingebed in gegevens en systemen expliciet uit te drukken. Zoals Guizzardi betoogt, is het niet genoeg dat representatietalen formeel expressief zijn - ze moeten gebruikers ondersteunen bij het articuleren en verifiëren van de werkelijke semantiek van hun modellen door middel van ontologische verplichtingen. OntoUML is zo'n taal - expliciet gefundeerd in de Unified Foundational Ontology (UFO) - die semantisch rijke, intern consistente en verifieerbare conceptuele modellering mogelijk maakt.
3.2.3. Implicaties voor datastations
Generiek versus specifiek: een spectrum van mapping-inspanning
Niet alle semantische interoperabiliteitsproblemen zijn even complex. Aan het ene kant van het spectrum bevinden zich generieke, breed gedeelde klinische gegevens — patiëntdemografie, diagnoses, medicatie, contacten, verrichtingen — waarvoor goed ingeburgerde standaarden (FHIR, OMOP CDM, SNOMED CT, LOINC, RxNorm) en steeds volwassener cross-model mappings al beschikbaar zijn. Aan het andere uiteinde bevinden zich zeer specifieke onderzoeksdomeinen — radiomics, multi-omics, gespecialiseerde biobankgegevens — waar minder consensus is over de gebruikte conceptuele modellen, codesystemen onvoldoende gedetaillerd zijn en het bereiken van semantische traceerbaarheid aanzienlijke inzet vereist van domein-experts. Datastationbeheerders moeten zich op dit spectrum positioneren en een implementatiestrategie kiezen die daarbijpast. Voor generieke data loont de investering in het hergebruiken of uitbreiden van bestaande mappings snel. Voor domein-specifieke onderzoeksvragen is de inspanning voor gedetailleerde ontologische mapping onvermijdelijk en, totdat voldoende volwassenheid is bereikt, is het doorsturen van data naar een centrale BVO voor integratie vaak de meest pragmatische keuze 2.
Bestaande mappings voor gangbare klinische gegevens
Voor gangbare klinische gegevens bestaat er al een groeiend ecosysteem van mappings, zowel in Nederland als internationaal. SSSOM (Simple Standard for Sharing Ontology Mappings) gecombineerd met SEMAPV (Semantic Mapping Vocabulary) biedt een gestandaardiseerd, machine-leesbaar formaat voor het vastleggen van deze mappings, inclusief hun herkomst, betrouwbaarheid en motivering. Bestaande mappings zouden met behulp van deze standaarden vastgelegd en onderhouden kunnen worden, bijvoorbeeld:
- DHD Diagnose- en Verrichtingenthesaurus — een Nederlandse ziekenhuiscoderingsthesaurus met potentieel voor gestandaardiseerde afstemming op ICD-10 en SNOMED CT.
- Z-Index naar RxNorm — het ErasmusMC heeft een mapping gemaakt van het Nederlandse Z-Index-geneesmiddelenregister naar RxNorm; Cornet et al. beschrijven de volledige keten van Z-Index → ATC → RxNorm.
- FHIR R4 ↔ OMOP CDM 5.4 — de meest volwassen cross-model mapping in het internationale klinische data-ecosysteem, geformaliseerd in de HL7 FHIR-OMOP Implementation Guide.
Bij het opschalen van datastations kan gedacht worden aan een nationale samenwerking om bestaande mappings in SSSOM + SEMAPV vast te leggen en deze herbruikbaar, citeerbaar en auditeerbaar maken voor alle deelnemende instellingen.
Een Rosetta Stone voor zorgdata-informatiemodellen
Geïnspireerd door de Rosetta Stone — het artefact dat het mogelijk maakte om te vertalen tussen voorheen incompatibele schriftsystemen — stellen wij voor een Rosetta Stone voor zorgdata te maken: een transparante, op standaarden gebaseerde vertaallaag tussen verschillende zorg-informatiemodellen. Als concreet voorbeeld implementeert plugin-rosetta dit patroon voor twee datamodellen in de klinische praktijk: FHIR R4 en OMOP CDM 5.4. Het illustreert hoe een Rosetta Stone voor generieke klinische data gebouwd en onderhouden kan worden.
De implementatie steunt op drie pijlers:
-
LinkML-schema's als gemeenschappelijke schemaklasse. Zowel de FHIR R4-resources als de OMOP CDM 5.4-tabellen worden beschreven als LinkML-schema's. LinkML biedt een technologieneutraal, leesbaar schemataal dat gecompileerd kan worden naar JSON Schema, RDF, OWL, Pydantic-modellen en meer. Door beide modellen in dezelfde schemataal uit te drukken, wordt het mappingoppervlak expliciet en auditeerbaar.
-
Annotatie van mappings als machine-leesbare mappingrecords. Binnen het LinkML-schema voor FHIR-resources draagt elk gemapped veld een mapping-annotatie die aangeeft of de koppeling met het OMOP-equivalent exact, breder of smaller is. Deze annotaties corresponderen direct met SSSOM-predicaten, waardoor de mapping is verankerd in een erkend standaardvocabulaire:
# fhir_resources.yaml (fragment) slots: gender: exact_mappings: - omop:gender_concept_id - omop:gender_source_valueDe mappings zijn afgeleid van de standaard HL7 FHIR-OMOP IG FML-structuurmaps, zodat elke mappingbeslissing herleidbaar is tot een gezaghebbende, versiebeheerde bron in plaats van een ad-hoc veld-voor-veld-keuze.
-
Drielaagse validatie. De uitvoer wordt gevalideerd op kolomniveau (schemarestricties), op recordniveau (Pydantic v2-modellen gegenereerd vanuit LinkML) en op semantisch niveau (LinkML
validate()). Deze gelaagde aanpak onderschept structuurfouten, typefouten en semantische constraintschendingen afzonderlijk, waardoor het eenvoudiger wordt om integratiefouten te diagnosticeren en op te lossen.
Hetzelfde Rosetta Stone-patroon — LinkML-schema's voor zowel bron- als doelmodellen, annotatie van mappings verankerd in SSSOM-predicaten, een upstream broncode als authentieke bron van gestandaardiseerde mappings — kan worden toegepast op andere gangbare modelparen in het Nederlandse zorgdatalandschap, zoals ZIB ↔ OMOP of DHD Thesaurus ↔ SNOMED CT.
Diepe ontologische afstemming voor specifieke onderzoeksvragen
Waar de Rosetta Stone-aanpak een pragmatische, herbruikbare oplossing biedt voor generieke data, vereisen specifieke onderzoeksvragen met complexe of betwiste semantiek een diepgaandere ontologische aanpak. Het Health-RI Semantic Interoperability Initiative biedt een rigoureus kader voor dit complexere probleem.
Het kader is opgebouwd rond de Health-RI Ontology (HRIO), ontwikkeld met een modelgedreven architectuur die betekenis en representatie van elkaar scheidt:
- HRIO OntoUML (CIM): een conceptueel model op de computation-independent laag, verankerd in de Unified Foundational Ontology (UFO). Domeinexperts gebruiken deze laag om te valideren dat de beoogde betekenis van concepten correct is vastgelegd, vóórdat computationele keuzes worden gemaakt.
- HRIO gUFO/OWL (PIM): een machine-leesbare OWL 2 DL-implementatie van dezelfde betekenissen op de platform-independent laag, geschikt voor redeneren en Semantic Web-integratie. Elke OWL-klasse erft zijn semantiek van zijn OntoUML-tegenhanger, waardoor betekenis en representatie over lagen heen traceerbaar blijven.
Externe ontologieën, terminologieën en schema's worden via het Health-RI Mapping Vocabulary (HRIV) op HRIO afgestemd. HRIV biedt een betekenisgerichte mappinglaag bovenop SSSOM en SKOS:
hriv:hasExactMeaning— de beoogde semantiek van het externe concept wordt volledig en nauwkeurig bepaald door het gekoppelde HRIO-concept (maximaal één per extern concept; impliceertskos:exactMatch).hriv:hasBroaderMeaningThan— het externe concept heeft een bredere betekenis dan het gekoppelde HRIO-concept (impliceertskos:narrowMatch).hriv:hasNarrowerMeaningThan— het externe concept heeft een smallere betekenis dan het gekoppelde HRIO-concept (impliceertskos:broadMatch).
Dit betekenisgerichte vocabulaire vermijdt de "valse overeenstemming"-valkuil die is beschreven in paragraaf 3.2.1: twee standaarden kunnen het label "Man" delen terwijl ze verschillende conceptualisaties hanteren (op karyotype gebaseerd versus op genderidentiteit gebaseerd). HRIV-mappings maken de beoogde semantische verplichting expliciet, in plaats van te vertrouwen op labelgelijkenis alleen.
De architectuurwinst is een semantische hub: in plaats van N×M paarsgewijze mappings te onderhouden tussen alle combinaties van standaarden en lokale schema's, mapt elk extern artefact eenmalig naar HRIO. Wanneer twee externe termen op dezelfde HRIO-betekenis mappen, worden hun beoogde semantieken vergelijkbaar via de gedeelde referentie — zonder dat voor elke combinatie een aparte paarsgewijze mapping nodig is. Alle mapping-artefacten worden gepubliceerd met stabiele, citeerbare persistente identificatoren (w3id), versiebeheerd via append-only supersessie (nooit overschreven) en bestuurd via een rolgescheiden reviewproces (Mapper ≠ Reviewer; Curator publiceert).
Voor specifieke domeinen zoals radiomics vereist het bereiken van dit niveau van semantische interoperabiliteit zeer specialistische kennis 3. Totdat voldoende ontologische volwassenheid is bereikt in dergelijke domeinen, blijft het doorsturen van data naar een centrale BVO voor deskundige integratie de meest pragmatische optie.
-
De tekst op deze pagina is grotendeels overgenomen uit het Semantic Interoperability initiatief van Health-RI. ↩
-
Varsha Gouthamchand, Ananya Choudhury, Frank J P Hoebers, Frederik W R Wesseling, Mattea Welch, Sejin Kim, Joanna Kazmierska, Andre Dekker, Benjamin Haibe-Kains, Johan van Soest, and Leonard Wee. Making head and neck cancer clinical data Findable-Accessible-Interoperable-Reusable to support multi-institutional collaboration and federated learning. BJR\textbar Artificial Intelligence, 1(1):ubae005, March 2024. URL: https://doi.org/10.1093/bjrai/ubae005 (visited on 2025-09-15), doi:10.1093/bjrai/ubae005. ↩
-
Petros Kalendralis, Zhenwei Shi, Alberto Traverso, Ananya Choudhury, Matthijs Sloep, Ivan Zhovannik, Martijn P.A. Starmans, Detlef Grittner, Peter Feltens, Rene Monshouwer, Stefan Klein, Rianne Fijten, Hugo Aerts, Andre Dekker, Johan van Soest, and Leonard Wee. FAIR-compliant clinical, radiomics and DICOM metadata of RIDER, interobserver, Lung1 and head-Neck1 TCIA collections. Medical Physics, 47(11):5931–5940, 2020. _eprint: https://aapm.onlinelibrary.wiley.com/doi/pdf/10.1002/mp.14322. URL: https://onlinelibrary.wiley.com/doi/abs/10.1002/mp.14322 (visited on 2026-01-09), doi:10.1002/mp.14322. ↩