Layers, pipes and patterns: detailing the concept of data stations as a foundational building block for federated data systems in healthcare
We generalize the concept of Personal Health Train in terms of the European Interoperability Reference Architecture, using the concept of a data station as a foundational building block. By conceptualizing data stations as persistent data storage within the domain of the Data Holder that is tightly integrated with decentralized computing resources, we outline steps towards interoperable federated analytics networks in healthcare.
personal health train, federated learning, data station, data systems, data engineering, lakehouse, Apache Arrow, Apache Parquet, Apache Iceberg, duckdb, polars
A shift towards federated data systems as a design paradigm
The ambition for a seamlessly connected digital healthcare ecosystem, capable of leveraging vast quantities of patient data remains illusive. Designing and implementing health data platforms is notoriously difficult, given the heterogeneity and complexity of such systems. To address these issues, federated data systems are gaining traction as an overarching design paradigm in which data to remains securely at its source and computations are performed in a decentralized, distributed fashion.
Recent technological inventions offer important new enablers to implement federated data systems, most notably:
- Significant increase in single-node computing capabilities, whereby it is now possible to process up to 1 TB of tabular data on a single machine node thereby enabling increasingly large volumes of data to be processed in a decentralized, federated system [1, 2];
- Maturity of federated analytics and specifically federated learning as a means of performing analysis whilst ‘hidding’ the data from third parties, including training of deep learning models through aggregation of weights [3–5];
- Privacy-enhancing technologies (PETs) such as secure multi-party computation (MPC) that are now sufficiently mature to be used on an industrial scale, enabling computations to be done under encryption (in-the-blind) thereby significantly improving security across a network of participants [6, 7];
- The composable data stack as a solution design that allows for unbundling of the venerable relational database into loosely coupled components, thereby making it easier and more practical to implement federated data systems using cloud-based components with microservices and thus opening up a transition path towards more modular and robust architectures [8, 9].
The architectural shift from centralized to federated data systems is not merely a technical evolution. Modern approaches to data governance are undergoing a similar paradigm shift towards federated solutions. Federated data systems are inherently more aligned with contemporary data governance frameworks, including the Data Governance Act (DGA), the European Health Data Space (EHDS) and the concept of data solidarity [10]. Within the context of large corporations, the concept of a data mesh is increasingly being adopted as well, which in essence is a federation of data producers and consumers within a commercial enterprise. From the perspective of sovereignty and solidarity, we believe that a commons-based, federated approach has distinct benefits in moving towards a more equitable, open digital infrastructure [11].
However, this ongoing paradigm shift towards is not without challenges. The notion of what constitutes a federated data system needs to be defined in more detail if we are to see the forest for the trees between different meanings of the same word. For example, ‘federation’ can refer to any of the following concepts:
- Data federation in de context of distributed databases addresses the problem of uniformly accessing multiple, possibly heterogeneous data sources, by mapping them into a unified schema, such as an RDF(S)/OWL ontology or a relational schema, and by supporting the execution of queries, like SPARQL or SQL queries, over that unified schema [12];
- Federation within the context of a Personal Health Train (PHT) refers to the concept where data processing is brought to the (personal health) data rather than the other way around, allowing (private) data accessed to be controlled, and to observe ethical and legal concerns [13–17], and is just one of many solutions designs that are collectively grouped as federated analytics [3];
- Federation in Trusted Research Environment (TRE) pertains to a mechanism for data sharing in a temporary staging environment within a network of research organizations through federations services such as localization and access [18];
- Federation in the context of data spaces, as described in the DSSC Blueprint 2.0, pertains to the support the interplay of participants in a data space, operating in accordance to the policies and rules specified in the Rulebook by the data space authority.
What then, is a viable development path out of this creative chaos?
Towards data availability for secondary use
Inspired by previous calls to action to move towards open architectures for health data systems [19, 20] and the notion of the hourglass model [19, 21, 22], we hypothesize that the concept of a ‘data station’ can be used as a foundational building block for federated data systems. A data station should provide a set of minimal standards (at the waist of the hourglass), thereby maximizing the freedom to operate between data providers and data consumers within the context of a health data space. Note that this approach has many similarities with the FAIR Hourglass [22, 23]. Our approach of data stations presented here focuses on enabling secondary data use of routine collected clinical data using the architecture of the Personal Health Train as a starting point [13–17]. The objective of this paper is to extend this architecture in order to address four design questions that are relevant in ongoing efforts to implement nation-wide federated systems.
Online transactional vs. analytical processing
First, it is well known data systems have different design an performance characteristics depending whether they are built for online transactional processing (OLTP) or online analytical processing (OLAP), as summarized in the Table 1 below (taken from [24]).
| Property | Transaction processing systems (OLTP) | Analytic systems (OLAP) |
|---|---|---|
| Main read pattern | Small number of records per query, fetched by key | Aggregate over large number of records |
| Main write pattern | Random-access, low-latency writes from user input | Bulk import (ETL) or event stream |
| Data modeling | Predefined | Defined post-hoc, either schema-on-read or schema-on-write |
| Primarily used by | End user/customer, via web application | Internal analyst, for decision support |
| What data represents | Latest state of data (current point in time) | History of events that happened over time |
| Dataset size | Gigabytes to terabytes | Terabytes to petabytes |
Current efforts to design and implement the EHDS in fact aims to support primary (i.e. OLTP) and secondary use (OLAP) in one go [25, 26]. This Herculean endeavour has spawned many initiatives to develop a coherent architecture and support implementation across Europe that ultimately should lead to interoperability in the broadest sense of the word, most notably:
- The Data Space Blueprint v2.0 (DSB2) by the Data Spaces Support Centre ([27]) that serves as a vital guide for organizations building and participating in data spaces.
- The Simpl Programme ([28]) that aims to develop an open source, secure middleware that supports data access and interoperability in European data initiatives. It provides multiple compatible components, free to use, that adhere to a common standard of data quality and data sharing.
- TEHDAS2 ([29]), a joint action that prepares the ground for the harmonised implementation of the secondary use of health data in the EHDS.
We believe, however, that in order to successfully design and implement health data spaces, more detailed analysis and solution patterns are required that distinguish between primary (OLTP) and secondary (OLAP) data use. Although functional components can be shared between these two, it is a matter of the devil being in the details. Hence one of the objectives of this paper is to detail an open, technology agnostic architecture for secondary use, to complement existing efforts and guide the development in the field.
Centralized vs decentralized processing
A second design question pertains to the choice between centralized or distributed c.q. decentralized platforms, which are not only be driven by technical considerations (scalability, elasticity, fault tolerance, latency) but are also strongly dependent on organizational, legal or regulatory requirements such as data residency. The general approach of EHDS and other data spaces is federative by nature, that is, decentralized. For example, DSB2 stresses the need for interoperability and federative protocols within and across data spaces.
Upon closer inspection, however, specific functional components that are foreseen within the EHDS are best characterized as centralized (sub-)systems. As an example, consider the secure processing environments (SPE) as defined in article 73 of the EHDS. Known examples of such SPEs include data platforms provided by national statistics offices (CBS Microdata environment), healthcare-specific national platforms (Finland’s Kapseli platform) and Trusted Research Environments (TREs) within the domain of research (see EOSC-ENTRUST for examples across Europe). Given that healthcare data is often vertically partitioned (data elements of the same subject are scattered across various data holders), SPEs provide the most effective means to (temporarily) share, integrate and analyse such data. Hence many SPEs are best described as centralized systems, and thus we need to take into account that data spaces constitute a hybrid architecture that includes both centralized and decentralized components. Thus a more detailed analysis is required to arrive at scalable solution patterns that combine centralized vs. decentralized processing in a larger federated health data system.
Solution patterns to populate data stations
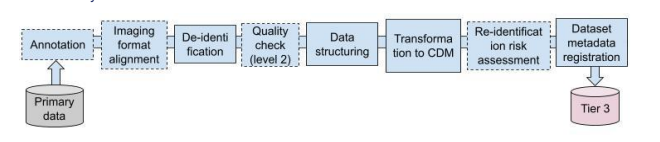
A third design issue pertains to the mechanisms through which the data stations are to be populated with data by the data holder. In essence the industry is converging towards solution patterns from data engineering and data warehousing where the data station is realized using the lakehouse architecture (see [30] and references therein). We stress the importance to difference between OLTP and OLAP systems where we envisage a data station for secondary use as an OLAP system. To illustrate this difference, consider the OpenHIE specification where the Shared Health Record is positioned as the data station for OLTP and the analytics datawarehouse as a separate OLAP functional building block that is populated using FHIR data pipelines [30, 31]. Figure 1 shows an example of such a setup, in this case for the imaging domain. The Extract-Transform-Load pattern of this pipeline includes various data (pre-)processing steps including image format alignment, de-identification and transformation to a common data model (CDM).
Federation as a system of systems
The fourth design challenge pertains to the need for having a ‘system of systems’ [32] in the federated health data system at large. In real-world setting, secondary health data sharing will need to take into account the limited resources and expertise of smaller health care providers. In fact, the EHDS explicitly addresses this issue in article article 50 that exempts micro enterprises from the obligation to directly participate in the EHDS, but that each member state may opt to form so-called data intermediaries to act as a go-between (recital 59). Along a different dimension, we foresee a system of systems of various regional or domain-specific federated networks that are loosely coupled, which poses design challenges in terms of autonomy (to what extend can each sub-network make independent choices), connectivity (how to connect sub-systems) and diversity.
Design questions framed within realization of Secure Processing Environments for secondary use
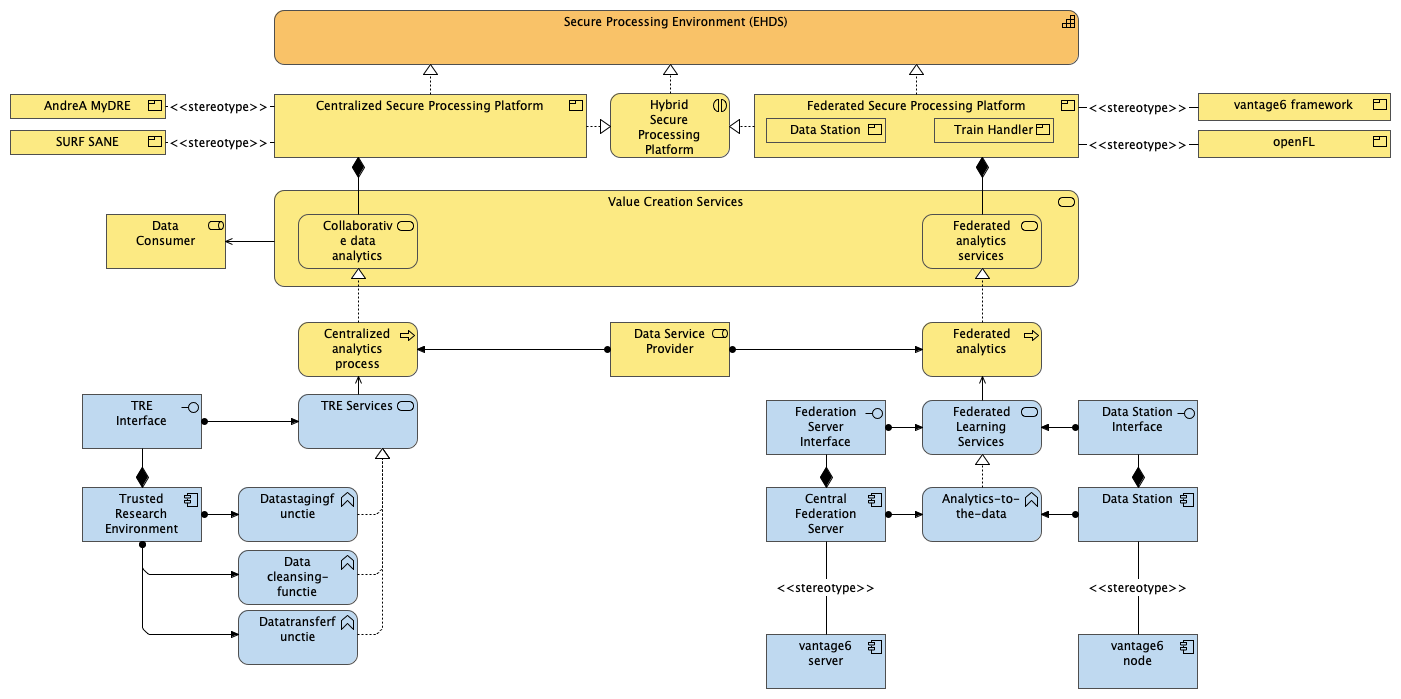
By addressing these four design questions, our aim is to specify the solution designs for a federated health data system with national coverage that can support secondary data use within the context of the EHDS. To clarify this objective, consider Figure 2 depicting the main concepts relevant to our paper in terms of an Archimate layered view. Starting from the top, the Secure Processing Environments (SPE) is taken as the key capability that needs to be realized as part of the EHDS. SPEs can be realized using different types of platforms, namely centralized, federated or hybrid. At the time of writing, we observe that there are already quite a few products available in the market, be it commercial or as an established open source project. The secure processing platforms (note we use platform to designate the business product vs. SPE to denote the capability) are composed of various value creation services as defined in the DSB2 (Figure 3). These services in turn are realized by underlying data analysis processes, which are envisaged to be supported by (Data) Service Providers.

Outline
With this overarching layered view in mind, we loosely follow an Action Design Research approach [33, 34] to address these design questions. Our main contributions are:
- A harmonized ontology of a data station and data hub, that integrates the PHT architecture [15, 17] into the European Interoperability Reference Architecture [EIRA] and the DSSC Blueprint 2.0
- Comparative analysis of existing implementations
- Synthesis of the above into functional and technical description of a data station in Archimate, thereby focusing on three primary software patterns [35]:
- the layers pattern for addressing various aspects of interoperability across the stack, including the Legal, Organizational, Semantic and Technical (LOST) framework as defined in EIRA and extending earlier work by [36] who have introduced five layers of interoperability specifically for PHT;
- the hub-and-spoke event broker topology pattern, where we generalize the concept of client-server federated analytics to formulate specifications for achieving interoperability across frameworks that leverage de facto standards for container orchestration with Kubernetes;
- the pipes and filters pattern for addressing various solution designs for the extract-transform-load (ETL) mechanisms through which data stations are populated, following the current common practice of datalakes and lakehouse solution designs [37–41];
- Proposals for new designs for specific domains, such as genomics or imaging.
- A reference implementation of data stations using the trains based on containers as a generic infrastructure for federated learning and federated analysis.
References
Citation
@article{2025,
author = {},
title = {Layers, Pipes and Patterns: Detailing the Concept of Data
Stations as a Foundational Building Block for Federated Data Systems
in Healthcare},
journal = {GitHub},
pages = {1-3},
date = {2025-06-01},
url = {https://github.com/health-ri/aida/data-stations/index.html},
langid = {en},
abstract = {We generalize the concept of Personal Health Train in
terms of the European Interoperability Reference Architecture, using
the concept of a data station as a foundational building block. By
conceptualizing data stations as persistent data storage within the
domain of the Data Holder that is tightly integrated with
decentralized computing resources, we outline steps towards
interoperable federated analytics networks in healthcare.}
}