Strategisch perspectief
Definities van AI in de zorg en het ontwikkelproces van AI
We maken een onderscheid tussen AI en machine learning, en tussen klinische en niet-klinische toepassingen van machine learning in de zorg. We introduceren CRISP-DM als het standaard proces voor het ontwikkelen van machine learning algoritmes. Deze definities zijn het startpunt voor de verhaallijn van AIDA.
Definitie van AI en machine learning in de zorg
Volgens de OECD en de AI Verordening is een AI systeem:
… a machine-based system that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments. Different AI systems vary in their levels of autonomy and adaptiveness after deployment.
en dus in het Nederlands
… een machine gebaseerd systeem dat is ontworpen om met verschillende niveaus van autonomie te werken en dat na het inzetten ervan aanpassingsvermogen kan vertonen, en dat, voor expliciete of impliciete doelstellingen, uit de ontvangen input afleidt hoe output te genereren zoals voorspellingen, inhoud, aanbevelingen of beslissingen die van invloed kunnen zijn op fysieke of virtuele omgevingen.
Deze definitie is erg breed. Om de scope van AIDA te bepalen maken we onderscheid tussen AI en machine learning, zoals in Figuur 1. Voor nu richten we ons op machine learning en vergelijkbare vormen van statistical learning. We plaatsen expliciet de ontwikkeling van autonome systeem (robotica) en reinforcement learning buiten scope van AIDA.
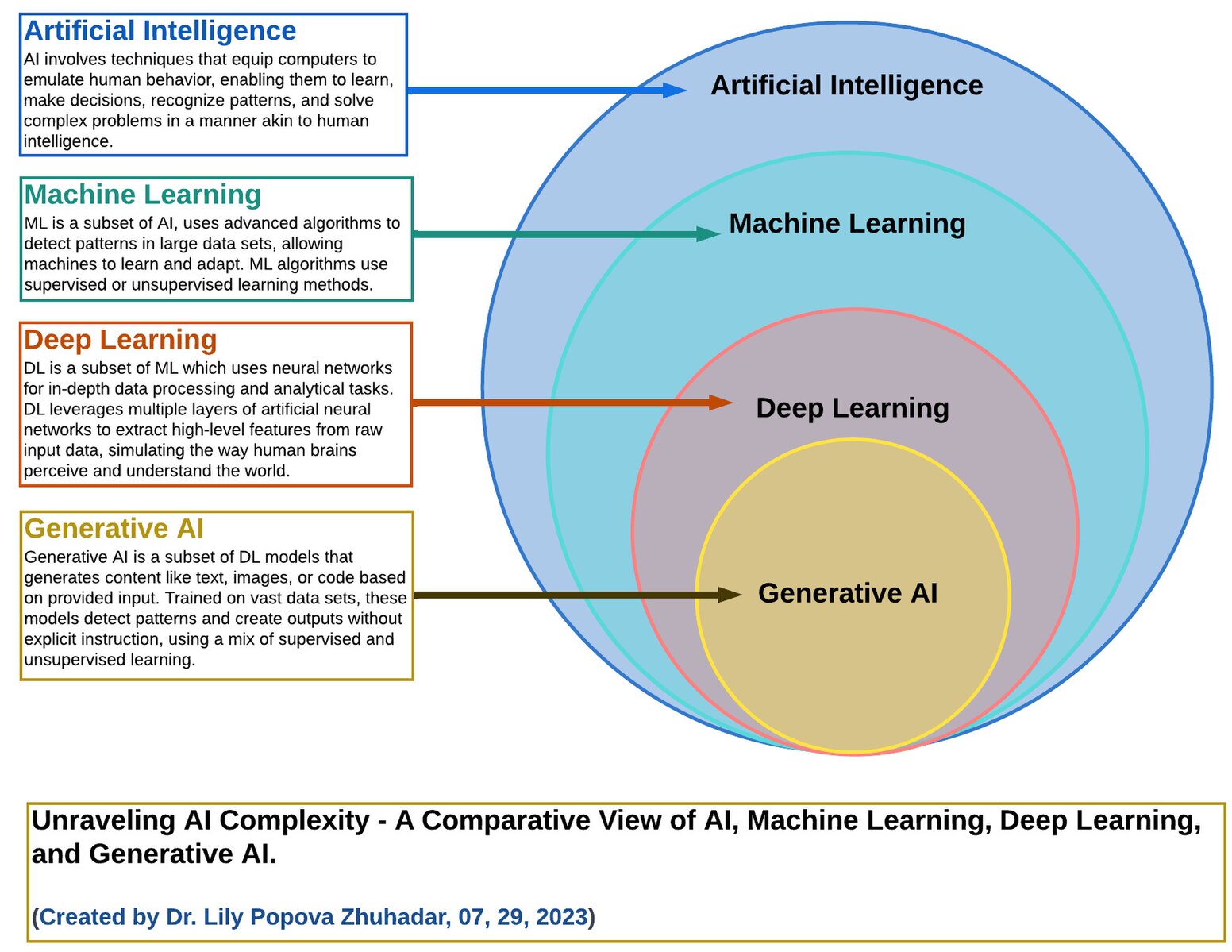
Binnen de zorg wordt vaak een onderscheid gemaakt tussen klinische en niet-klinische (lees: bedrijfsmatige) toepassingen van AI
Klinische machine learning toepassingen
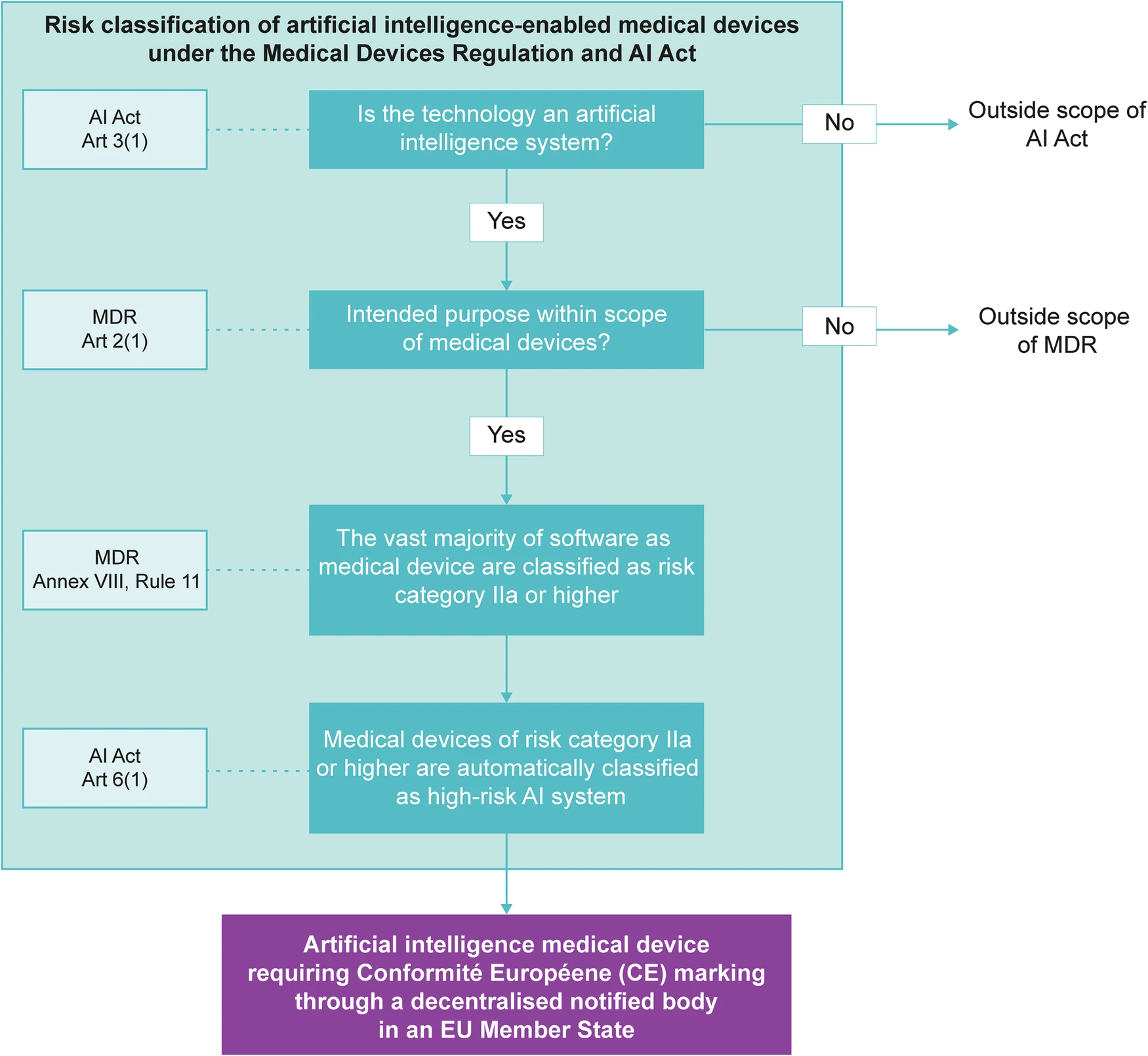
- Scope van de Leidraad AI in de zorg AI Prediction Algorithm (AIPA): voorspelling over (toekomstige) gezondheidstoestand
- Valt vaak in hoog risico categorie (zie stroomschema Figuur 2)
Machine learning voor bedrijfsmatige toepassingen (niet klinisch)
- Logistieke optimalisatie:
- voorspellen van ontslagmoment intensive care (Pacmed Critical)
- voorspellen ligduur spoedeisende hulp (EZA)
- voorspellen no-shows polikliniek (ErasmusMC)
- Verminderen van administratie- en registratielast
- Enorme groei in gebruik generatieve AI
- LLMs voor NLP taken (Sensire, ETZ)
- Speech-to-text (Autoscriber, Juvoly)
- Vrije tekst omzetten in gestructureerde data (Healthsage AI)
- AI ondersteund coderen (DHD)
Benodigde resources van verschillende AI toepassingen
tabulaire data –> beelden –> NLP (met pre-trained modellen) –> trainen fondationational GenAI models, Omics
ook relateren aan verwachte aantal gebruikers/use-cases
Het standaard ontwikkelproces voor machine learning: CRISP-DM
Het ontwikkelen, trainen en evalueren van machine learning algoritmes wordt gedaan aan de hand van een standaard proces. De CRISP-DM methode is hiervan de meest gebruikte (zie Figuur 3). [1] beschrijft hoe andere procesmodellen voor problem solving zoals Six Sigma DMAIC and PDCA ook hiervoor gebruikt kunnen worden. Aan de hand van dit proces schetsen wij hoog over wat AIDA zoal moet kunnen ondersteunen
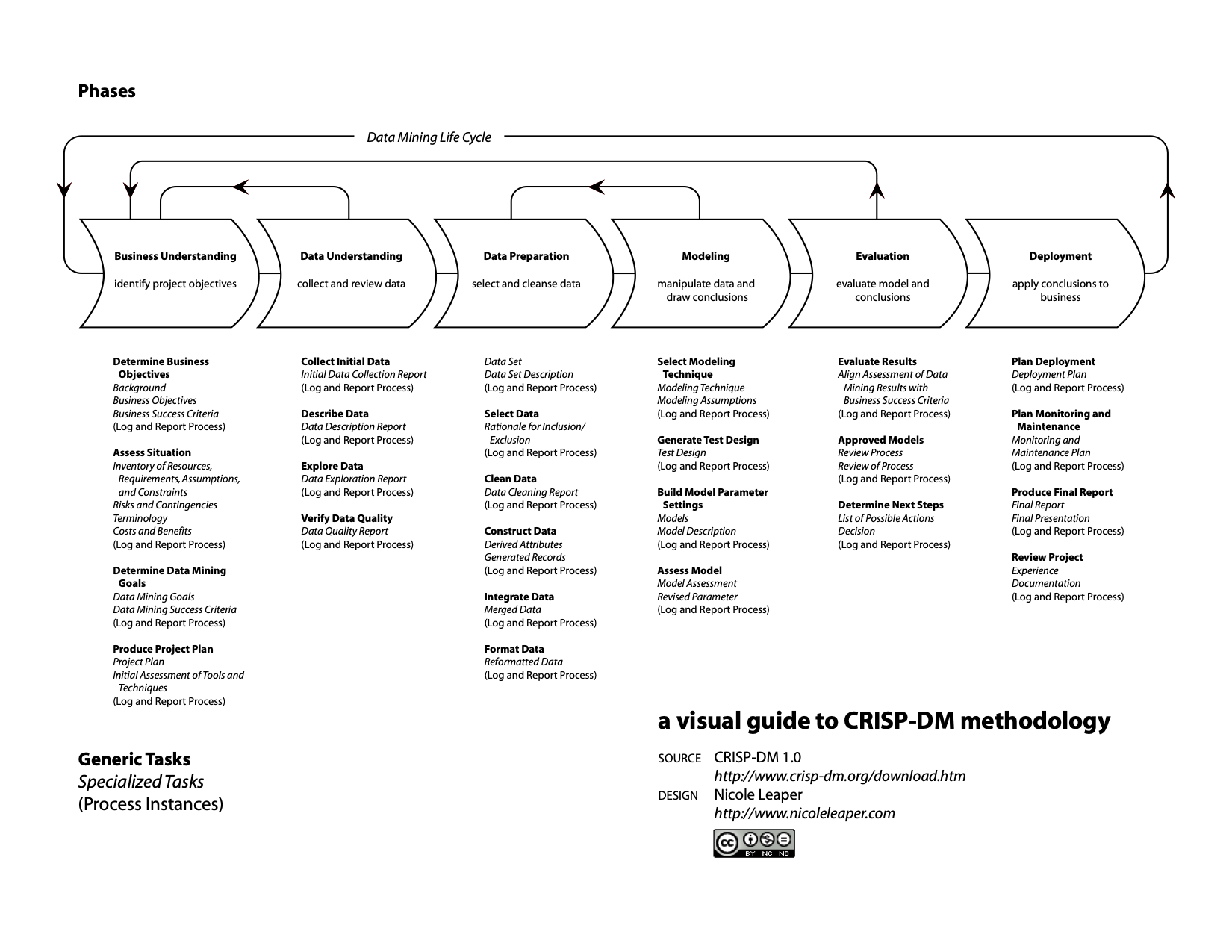
Exploratieve data analyse (EDA)
Omvat eerste twee fases, Business Understanding en Data Understanding. Een onderzoeker of een innovator moet kunnen ‘bladeren’ door de beschikbare data. Een van de resultaten van deze fase is dat een dataset wordt gedefinieerd, wat onderscheidend kenmerk is t.o.v. algemene data beschikbaarheid (primair gebruik). In verder ontwikkeling van AI is het essentieel dat we een dataset moeten kunnen ‘bevriezen’, annoteren en FAIR geschikt maken voor hergebruik door andere onderzoekers of voor responsible AI/goedkeuring van een algoritme.
De exploratieve data analyse heeft een belangrijk raak-/koppelvlak met het domein van databeschikbaarheid. Data gebruikers moeten ondersteund worden om te kunnen verkennen welke data beschikbaar is, en hoe met de aangeboden data gewerkt kan (en moet) worden. Binnen AIDA zullen hiervoor richtlijnen en/of standaarden worden opgezet.
Data Preparation en Modeling
Dit is de kern van het machine learning ontwikkeling. Veel verschillende libraries moeten beschikbaar zijn omdat er veel verschillende use-cases zijn, dus b.v.:
- data preparation: allerlei verschillende soorten ‘data wrangling’ libraries, afhankelijk van de voorkeuren van de gebruiker
- feature stores en vector databases: voor het ontwikkelen van grote modellen wordt gebruik gemaakt van intermediare respresentaties van de data. Tekst wordt b.v. omgezet naar vector embeddings. Deze wil je niet elke keer opnieuw willen bereken, dus er is specifieke (tijdelijke) opslag nodig
- verschillen machine learning libraries, zoals tabulaire machine learning (tree-based methods, tijdsreeksen) of deep learning (tensorflow, pytorch)
Evaluation
Dit is direct gerelateerd aan de overgang van pilot naar eerste klant. Een technisch correct algoritme zal een langer proces van validatie in de klinische praktijk moeten doorgaan, alvorens het breed uitgerold kan worden. AIDA dient mogelijkheden te bieden voor het verzamelen en bewaren van feedback uit field trials over het gebruik van ontwikkelde algoritmes.
Deployment
Idealiter biedt een landelijke voorziening als AIDA ook de mogelijkheid om een getraind model te hosten, zoals bijvoorbeeld Evidencio dat nu biedt voor (kleine) modellen voor medical decision support
Scope AIDA
- Ondersteunen beide soorten. Voor een uitgebreider overzicht, zie [2]
- Uitdaging is dat afhankelijk van de soort machine learning dat ontwikkeld wordt, de functionele eisen van AIDA anders zijn. Concreet: het trainen van een relatief eenvoudige classificatie model op een dataset van 10.000 patienten vereist veel minder rekenkracht dan b.v. het trainen van een foundational LLM met gebruik van klinische teksten uit EPD
- Machine learning vatten we breed op, dus het omvat ook andere vormen van statistical learning en problem solving (zie [1]). Naast machine learning dient AIDA ook gebruikt te kunnen worden voor
- Causal inference, Bayesian inference, structural causal modeling
- Deductieve modellen, zoals vaak in operations research worden gebruikt